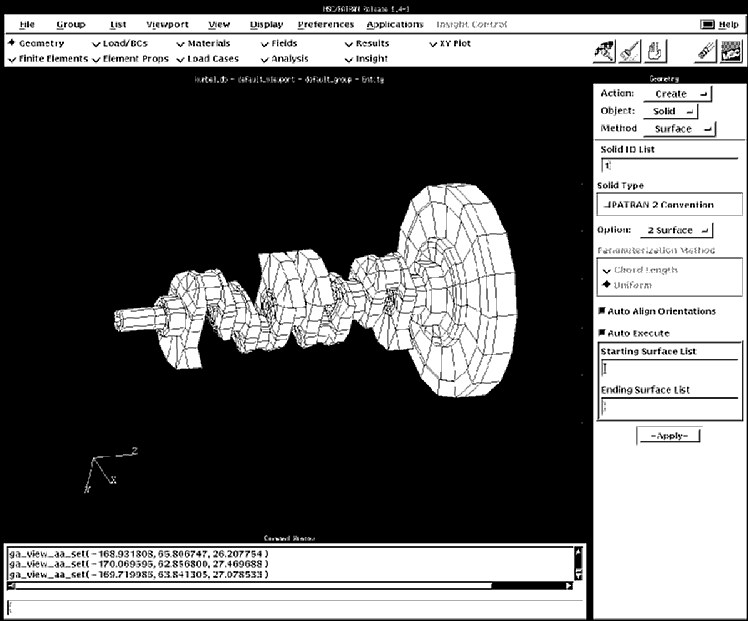
Das Bild zeigt eine mit PATRAN erzeugte Kurbelwelle (Siehe dazu Text unten)
IMPRESSUM
Herausgeber: Prof. Dr. Adolf Schreiner
Redaktion: Ursula Scheller, Klaus Hardardt
Erscheinungszeitraum: monatlich
Tel.: 0721/608-4865
e-mail: scheller@rz.uni-karlsruhe.de,
hardardt@rz.uni-karlsruhe.de
Rechenzentrum der Universität Karlsruhe
Postfach 6980
Zirkel 2
76128 Karlsruhe
INHALT
Rent-a-HiWi! - unter diesem Schlagwort bietet das RZ seinen Kunden eine neue, zusätzliche Serviceleistung an. Ab sofort können Sie bei uns qualifizierte wissenschaftliche Hilfskräfte anfordern, wenn Sie Probleme mit Ihrem PC oder Ihrer Workstation haben und einfach nicht mehr weiter wissen.
Fragen wie "ich krieg' das Netzwerk nicht zum Laufen, was mach' ich falsch?" oder "welche Software brauche ich, um ans Netz zu kommen?" tauchen immer häufiger auf. Eine telefonische oder auch persönliche Beratung im RZ reicht da oft nicht aus, da die Lösung des Problems häufig von vielen Faktoren physikalischer und logischer Art abhängt, und nur ein versierter Experte vor Ort die richtigen Entscheidungen und Maßnahmen treffen kann. Mit der zunehmenden Vernetzung hat sich diese Problematik nun noch verschärft.
Auch Probleme mit der Installation von Betriebssystemen und Anwendungspakteten sind meist konfigurationsbedingt und können nur vor Ort schnell erkannt werden. Bisher hat sich das RZ in diesen Fällen auf das umfassende Beratungsangebot der Mitarbeiter/innen, der Programmierberatung und von Micro-BIT gestützt. Hausbesuche von Mitarbeiter/innen und wissenschaftlichen Hilfskräften waren eher die Ausnahme. An dieser Stelle möchten wir nun unseren Service erweitern und gezielt zu einem von jedem(r) Institutsmitarbeiter/in abrufbaren Vor-Ort-Service übergehen. Für diesen Service wird pro Stunde eine Gebühr in Höhe des Stundenlohnes einer wissenschaftlichen Hilfskraft von ca. 20.- DM in Rechnung gestellt. Diese Dienstleistung ist hauptsächlich für PC- und Workstation-Nutzer gedacht, die Probleme mit der Installation von Hard- und Software oder bei Netzwerkeinbindungen haben. Soweit möglich werden auch Fehlerbehebungen vorgenommen. Angefordert werden können die Fachkräfte über den WWW-Server des RZ
Unser Tip: beim nächsten Problem versuchen Sie es doch einmal mit uns!
Wie in der Benutzerversammlung am 27.6.1995 bereits angekündigt wurde, ist das Rechenzentrum wegen der gestiegenen Wartungskosten gezwungen, die Prozessoren des Vektorrechners SNI S600/20 zum Jahresende durch neue Prozessoren zu ersetzen.
Die neuen Prozessoren sind wegen der Realisierung in CMOS-Technologie in den Betriebskosten deutlich niedriger als die alten Prozessoren, so daß trotz höherer Rechenleistung niedrigere Betriebskosten anfallen.
Nach dem derzeitigen Stand der Planung ist die Anlieferung für Dezember 1995 vorgesehen. Nach der Installation des Betriebssystems und der Einrichtung der lokalen Betriebsumgebung können die Anwenderprogramme portiert werden. Bis Ende Februar 1996 sollten diese Arbeiten abgeschlossen sein, da die Lauffähigkeit der bisherigen Codes nur bis Ende Februar gewährleistet werden kann.
Für August 1996 ist eine weitere Reduzierung der Zykluszeiten vorgesehen. Der Rechner in seiner neuen Konfiguration stellt sich dar als Vektorprozessorsystem, das 4 Processingelemente (PE) umfaßt. Die Architektur der einzelnen PEs ist der Architektur der bisherigen Prozessoren sehr ähnlich, so daß optimierte Programme auch weiterhin mit hoher Effizienz laufen werden.
Jedes PE ist mit einem Hauptspeicher von 2 GB, einer Skalareinheit (SU) und einer Vektoreinheit (VU) ausgestattet. Die SU arbeitet nach dem RISC- Prinzip, so daß mehrere Instruktionen parallel abgearbeitet werden können, was zu einer maximalen Instruktionsrate von 300 bzw. 400 MIPS führt. Die VU beinhaltet je eine Load-, Store-, Add/Logical-, Multiply- und Divide-Pipeline, zwei Mask-Piplines sowie dynamisch konfigurierbare Vektorregister von insgesamt 128 KByte Größe mit dazu passenden Maskenregistern.
Die Spitzenleistung einer VU beträgt 1,6 bzw. 2,2 GFLOPS, so daß die Gesamtleistung mit 6,4 bzw. 8,8 GFLOPS deutlich über der bisherigen Leistung von 5 GFLOPS liegt. Die interne Zahldarstellung entspricht dem IEEE 754 floating point standard während die Daten bisher im sog. IBM-Format gespeichert wurden. Ein Austausch von Binärdaten mit Workstations ist deshalb problemloser möglich.
Mit der Umrüstung der Hardware geht eine Neuinstallation der Software einher. Das neue Betriebssystem UXP/V ist eine Weiterentwicklung des bisherigen Betriebssystems UXP/M. Vektorisierende Compiler stehen für Fortran 90 und C zur Verfügung, die Source-Code-kompatibel zu dem bisherigen Fortran 77- bzw. C-Compiler sind. Das Rechenzentrum wird die Unterprogrammbibliotheken BLAS, LAPACK, FIDSOL/ CADSOL, VECFEM, LAPACK, RAND/VP und FFT/VP bereitstellen. Außerdem ist davon auszugehen, daß eine Version der NAG-Library verfügbar sein wird. Die IMSL-Bibliothek wird wegen der geringen Nutzung nicht weiter unterstützt werden. Die Finite-Elemente-Programme ABAQUS, FIDAP und NASTRAN können zunächst noch nicht unter UXP/V angeboten werden. Das Rechenzentrum bemüht sich jedoch, vergleichbare Compute-Server für diese Pakete bereitzustellen. Entsprechende Freigabeanträge sind beim Ministerium gestellt.
Um Anwendungsprogramme zu portieren, ist i.a. nur eine Neuübersetzung notwendig, wobei jedoch Maschinenkonstanten, die von der internen Zahldarstellung abhängen, anzupassen sind. Binärdaten (z.B. Restart-Files) müssen in die IEEE-Zahldarstellung gewandelt werden, was mit entsprechenden Laufzeitoptionen beim Schreiben bzw. Lesen der Daten möglich ist. Ob bei der Übertragung von Binärdaten Probleme zu erwarten sind, kann schon jetzt überprüft werden, indem die Daten auf einer Workstation eingelesen werden.
Bei weiteren Fragen wenden Sie sich bitte
Seit dem 18. September 1995 ist die neuinstallierte Glasfaserverbindung in die Westhochschule in Betrieb, die Laserstrecke wurde abgeschaltet. Damit ist die Anbindung des Westcampus an das übrige Netz der Universität (nun) ebenso stabil wie Verbindungen innerhalb des Ostcampus.
Die Strecke zur Westhochschule hat eine maximale Bandbreite von 10 Mbit/s und ist in Form eines Ethernetsegments realisiert. Die Auslastung der Verbindung (in der Vergangenheit ungefähr 1 Mbit/s) muß natürlich noch beobachtet werden. Sollte es zu Engpässen kommen, kann die Glasfaserstrecke (unter Einsatz neuer aktiver Netzkomponenten auf beiden Seiten) auch mit erheblich höheren Geschwindigkeiten genutzt werden.
In Kürze wird auch die Verbindung zur Fachhochschule (64kbit/s) auf Glasfaser umgeschaltet. Danach steht hier ebenfalls eine Bandbreite von 10 Mbit/s zur Verfügung.
Reinhard Strebler, Tel. -2068 e-mail: Strebler@rz.uni-karlsruhe.de.
Das Wachstum Netzes
Das World Wide Web ist ein ständig wachsendes Netz, und noch scheint es so,
als seien dem Wachstum keine Grenzen gesetzt.
Kein Internetdienst zuvor hat je einen solchen Boom erlebt.
Seit der Veröffentlichung von
Mosaic
Ende 1993 scheint die Zahl der WWW-Server ins Unermeßliche zu steigen.
Mit der wachsenden Zahl der WWW-Server steigt auch die Menge der
angebotenen Informationen, und, entscheidender, die Menge der
übertragenen Informationen, die durch die steigende Akzeptanz
(und die steigende Brauchbarkeit) des World Wide Web
als Informationsmedium noch zusätzlichen Vorschub erfährt.
Das World Wide Web hat sich inzwischen als der weltweit
populärste Dienst auf dem Internet etabliert und sogar FTP überflügelt.
Als Benutzer der Korn- oder Z-Shell oder der Bash kann man z.B. folgendes in sein
Netscape übernimmt zwar beim ersten Aufruf die Werte aus
diesen Variablen, erkennt nachträgliche Änderungen aber nicht mehr.
Hier müssen die entsprechenden Eintragungen in den Preferences erfolgen.
Die Eintragung erfolgt nicht wie bei den Variablen als URL, sondern
getrennt nach Host und Port, hier muß
Auch Netscape wird über die
Preferences konfiguriert,
getrennt nach Host und Port; hier muß
Die Konfiguration von Netscape entspricht der auf den anderen Plattformen; es muß
Entities fangen mit einem Ampersand (
Ein typisches Dokument sollte also so aussehen:
Das wichtigste Element im Header ist der Titel des Dokuments, er wird
mit
Ein weiteres wichtiges Element is das
Der Header ist mit
Einfacher Fließtext kann aber nur begrenzt eine Aussage vermitteln.
Deshalb gibt es in HTML zusätzliche Tags, mit denen man etwas über die
Struktur und den Inhalt eines Dokuments aussagen kann.
Diese Struktur wird dann vom Browser in ein Layout übertragen,
das aber von Browser zu Browser unterschiedlich sein kann.
Man sollte beim Schreiben eines HTML-Dokuments also immer darauf achten,
daß es von unterschiedlichen Programmen ganz unterschiedlich dargestellt
werden kann.
Insbesondere Sätze wie "Klicken Sie mit der Maus auf die blauen
unterstrichenen Wörter" sind für Leser, die nur ein ASCII-Terminal
haben und mit den Cursortasten fett geschriebene Wörter auswählen müssen,
äußerst verwirrend.
HTML-Tags dienen also nur einer semantischen Gliederung des Dokuments
und geben dem Browser Hinweise über den Inhalt, die dieser dann in eine
seinem Benutzer angenehme Darstellung übersetzt.
Abschnitte werden i. A. durch einen Abstand voneinander getrennt.
Ab und an kann es notwendig werden, eine neue Zeile anzufangen, ohne
einen Abstand zu erzeugen; für diesen Zeilenumbruch dient
der
Eine deutlichere Trennung mehrerer unabhängiger Teile eines Dokuments
kann man durch das Einsetzen einer horizontalen Linie erreichen.
Sie wird mit dem
Eine besondere Art des Abschnitts ist ein Zitat oder ein Beispiel.
Hierzu dienen die
Der dritte Typ unterscheidet sich von den vorherigen dadurch, daß ein
Eintrag aus zwei Teilen besteht: einem Eintrag und einer zugehörigen
Beschreibung.
Eine solche Liste läßt sich als Glossar u. ä. verwenden.
Das Schlüsselwort wird dabei durch
Um jetzt konkret einen Hyperlink anzugeben, benutzt man die
Zum Einbinden von Bildern dient der (leere)
Nicht jeder Browser hat die Möglichkeit, Bilder anzuzeigen; darauf sollte
man Rücksicht nehmen.
Insbesondere sollte man solche Bilder vermeiden, die lediglich der Dekoration
dienen sollen; meist dienen sie nur der Erhöhung der Netzlast oder
zerstören das Bild, weil ein frustrierter Benutzer am anderen Ende der
langsamen Leitung die Darstellung der Bilder abgeschaltet hat.
Andererseits gibt es Bilder, die wichtige Informationen enthalten, die
dann aber Benutzern nicht graphikfähiger Browser entgehen.
Diesen sollte man wenigstens einen Hinweis auf den Inhalt des Bildes
geben, indem man einen alternativen Text im
In der letzten Zeit hat eine so rasante Entwicklung im EDV-Bereich stattgefunden, daß sich das Aufgabenfeld des Rechenzentrums entscheidend verlagert hat. Auch die Betriebsabteilung des RZ ist von diesen tiefgreifenden Veränderungen stark betroffen. Während der Betrieb in der letzten Dekade hauptsächlich Aufgaben zu erfüllen hatte, die im Zusammenhang mit den hier installierten Großrechnern standen, ist durch die Dezentralisierung von Rechnern eine Vielzahl von neuen Aufgaben entstanden. Unter anderem sind die Wartung der auf dem Campus verteilten Workstations und die Überwachung der verschiedenen Netzwerke in die Verantwortung des Operatings übergegangen - um nur zwei Beispiele zu nennen. Generell müssen weniger Routinearbeiten erledigt werden, während der Kontakt zu Kunden des Rechenzentrums zugenommen hat. Die neuen Aufgaben im Betrieb sind nicht nur durch eine fortschreitende Diversifizierung gekennzeichnet, sondern auch dadurch, daß eine höhere Qualifizierung der Mitarbeiter unerläßlich ist. Daher hat das Rechenzentrum technische Fortbildungsmaßnahmen mit großem Erfolg forciert, die hausintern vorbereitet und durchgeführt wurden. So wurden z. B. ein UNIX- und ein Netzwerküberwachungskurs veranstaltet.
Diese Maßnahmen haben gezeigt, daß es dringend notwendig war, die Englischkenntnisse der Mitarbeiter im Betrieb zu verbessern, da alle Computermeldungen und Manuals in Englisch verfaßt sind. Eine Schulung in Englisch sollte den Betrieb sicherstellen und einer Gefährdung der Beschäftigung der Mitarbeiter vorbeugen.
Die Ausbildung mußte einerseits auf die spezielle Vorbildung und andererseits auf die speziellen Aufgaben abgestimmt sein. Solche Englischkurse werden weder von Volkshochschulen noch von universitätsinternen Einrichtungen angeboten. Daher wurden von Oktober 1994 bis April 1995 auf die Bedürfnisse der Betriebsabteilung abgestimmte Kurse erarbeitet und durchgeführt. Die zwingenden Gründe für diese Maßnahme seien nochmal zusammengefaßt:
Nach der Überprüfung der Englischkentnisse der Mitarbeiter stellte sich die Notwendigkeit heraus, Kurse mit unterschiedlichem Schwierigkeitsgrad zu halten. Es fanden zwei Kurse im Umfang von je zwei Wochenstunden für einen Zeitraum von sechs Monaten statt, die auch von Mitarbeitern der Abteilungen Technik und Geschäftsführung besucht wurden. Die Kursinhalte wurden von einer ausgebildeten Englischlehrkraft erarbeitet. Dafür waren drei Monate reserviert.
Die in diesem Ausbildungsprogramm gewonnenen Erkenntnisse und Kursunterlagen werden anderen Universitätsrechenzentren und Einrichtungen zur Verfügung gestellt, die vor derselben Problematik stehen. Sie werden in Kürze als interne Berichte des Rechenzentrums Nr. 57/95 und Nr. 58/95 über WWW unter der URL-Adresse
Frau Sämann, die mit großem Engagement und völlig selbständig die Kurse vorbereitet und durchgeführt hat, möchte ich an dieser Stelle recht herzlich danken. Dabei ist hervorzuheben, daß es für ihre schwierige Aufgabe keinerlei Unterlagen und Erfahrungen gab. Herr Prof. Schreiner ermöglichte durch seine Unterstützung als Leiter des Rechenzentrums überhaupt erst die Konzeption und Realisierung dieser Kurse. Dafür sei ihm besonders gedankt. Mein weiterer Dank geht an die Mitarbeiter des Betriebs des Rechenzentrums der Universität Karlsruhe, ohne deren Mitarbeit diese Weiterbildungsmaßnahme nicht möglich gewesen wäre.
Die Abteilung ``Numerikforschung für Supercomputer'' unter der Leitung von Prof. Dr. Willi Schönauer konnte Herrn Miroslav Rozloznik, Akademie der Wissenschaften, Prag, Tschechien, für einen Forschungsaufenthalt von 12 Tagen im Juli 1995 als Gast begrüßen.
Zwischen der Akademie der Wissenschaften, Prag, Tschechien, und dem Rechenzentrum der Universität Karlsruhe bestehen seit der Wende Kontakte. Herr Rozloznik schreibt zur Zeit am Institut für Informatik der tschechischen Akademie seine Doktorarbeit über iterative Gleichungslöser. In einem Teil dieser Arbeit wird die Stabilität von Implementierungen für fehlerminimierende Verfahren, die von Dr. Weiß am Rechenzentrum der Universität Karlsruhe entwickelt wurden, untersucht.
Viele Probleme der Physik, der Ingenieurwissenschaften, der Medizin und Chemie lassen sich durch Systeme partieller Differentialgleichungen beschreiben. Die numerische Lösung dieser Systeme mit den Methoden der finiten Elemente, der finiten Differenzen oder der Randelemente führt auf die Lösung extrem großer linearer Gleichungssysteme. Um diese Systeme in akzeptabler Zeit lösen zu können, sind sowohl die schnellsten Computer als auch die modernsten numerischen Verfahren nötig. Die fehlerminimierenden Verfahren sind neue numerische Algorithmen mit bemerkenswerten Eigenschaften und können darüberhinaus effizient vektorisiert und parallelisiert werden. Daher sind sie sehr geeignet für die Anwendung auf heutigen Superrechnern.
Am Rechenzentrum ist wenig Raum für rein theoretische Untersuchungen. Hier ergänzen die theoretischen Untersuchungen der Akademie der Wissenschaften in idealer Weise die hier am Rechenzentrum aus der Praxis heraus entwickelten Verfahren. Andererseits sind zum Praxistest der theoretischen Beiträge von Herrn Rozloznik, die neue und stabile Implementierungen einführen und untersuchen, Rechner nötig, die in Tschechien nicht verfügbar sind. Diese Tests konnten am Rechenzentrum der Universität Karlsruhe durchgeführt werden.
Im Jahr 1994 besuchte Herr Rozloznik für eine Woche die Abteilung ``Numerikforschung für Supercomputer'' am Rechenzentrum der Universität Karlsruhe. Während dieses Aufenthalts wurden erste Tests für neue Implementierungen fehlerminimierender Verfahren auf dem Karlsruher Vektorrechner SNI S600/20 durchgeführt. Die Arbeiten wurden anschließend sowohl in Prag als auch in Karlsruhe weitergeführt.
Bei dem diesjährigen Aufenthalt von Herrn Rozloznik wurden auch für sehr große und schlecht konditionierte Matrizen stabile Implementierungen sowohl theoretisch begründet als auch praktisch nachgewiesen. Darüberhinaus konnte gezeigt werden, daß die fehlerminimierenden Verfahren für bestimmte Probleme konkurrenzlos gut sind.
Diese Arbeiten haben nun ihren Abschluß gefunden und sind in dem internen Bericht des Rechenzentrums Nr. 56/95, M. Rozloznik and R. Weiß, "On the stable implementation of the Generalized minimal error method", dokumentiert. Der Bericht kann über WWW unter der URL-Adresse
Endlich, nach langer Wartezeit kann das bisherige, etwas angestaubte PATRAN 2.5, für das nur eine limitierte maschinengebundene Lizenz existierte, durch das neue P3/PATRAN ersetzt werden. Das Rechenzentrum hat eine Lizenz für 7 gleichzeitige Nutzer auf HP9000 Workstations erworben.
Zur Erinnerung: P3/PATRAN ist der Finite Elemente Prä-und Postprozessor innerhalb des MSC/PATRAN-Systems. Mit ihm kann man
Die Benutzeroberfläche basiert auf Motif und die Struktur des Programms hat sich geändert, sodaß Kenner von PATRAN II sich umstellen müssen. Im folgenden einige Charakteristika von P3/PATRAN:
P3/PATRAN kann z.Z. auf den HP9000-Maschinen im RZ-Pool (Raum -112) und im DT-Pool aufgerufen werden. Um P3/PATRAN auch in anderen Pools oder auf institutseigenen Maschinen verfügbar zu machen, muß lokal ein Client installiert werden. Interessenten mögen sich bitte mit mir in Verbindung setzen (Tel. -4035, e-mail: paul.weber@rz.uni-karlsruhe.de). Weitere Informationen findet man im WWW-Server unter
Das Programm ftnchek (Fortran Program Checker) ist ein sehr leistungsfähiges Werkzeug, das die Erstellung und Wartung von Fortran 77 Programmen unterstützt. Insbesondere kann ftnchek dazu eingesetzt werden, Fehler festzustellen, die durch falsche Parameterübergabe beim Unterprogrammaufruf verursacht werden. Dies war bislang jedoch nur für Programme möglich, die im Quelltext vorliegen. Um diese Funktion auch für die vom RZ bereitgestellten Unterprogrammbibliotheken nutzen zu können, wurden sogenannte Project Files erstellt, die die notwendigen Informationen über die Parameterübergabe enthalten.
Wie der entsprechende Aufruf von ftnchek lautet, sowie weitere Informationen zu ftnchek und anderen auf den HP- bzw. IBM-Workstations installierten Dienstprogrammen zur Unterstützung der Fortran-Programmierung findet man im WWW unter der URL:
Im Rahmen der erweiterten Landeslizenz für die NAG-Bibliothek wurde jetzt auch die NAG Fortran 90 Library auf den vom RZ administrierten Workstations installiert. Diese Bibliothek wurde unter Benutzung der neuen Sprachelemente von Fortran 90 (Module, generische Prozedurnamen, benutzerdefinierte Datentypen etc.) völlig neu konzipiert.
Weitere Informationen zu dieser Bibliothek sind im WWW unter der URL
Ab sofort kann mit dem Programm XV das Photo-CD-Format gelesen werden. Die Dokumentation ist beim Studentenwerk für 3,50 DM erhältlich. Das Programm können Sie mit dem Kommando
In der Zeit vom 6.-9. November findet wieder ein Einführungskurs in ABAQUS 5.4 statt.
Datum: 6.11. bis 9.11.1995
Es werden keine speziellen Anforderungen an die Kursteilnehmer gestellt.
Programm:
2. Tag:
Ab dem Wintersemester 95/96 wird die Betriebsweise des AB-Pools (MAC-Nachfolge-Pool) in wichtigen Aspekten umgestellt:
Dazu veranstaltet das Rechenzentrum am Donnerstag und Freitag, den 5.10.95 und 6.10.95, einen Einführungskurs in die Benutzung des DCE und des Batchsystems LoadLeveler. Die Veranstaltung richtet sich an Betreuer der im Wintersemester im Ausbildungspool stattfindenden Kurse und an Benutzer, die im Ausbildungspool im Batchbetrieb rechnen wollen. Am Donnerstag wird zunächst eine Einführung in DCE und DFS und am Freitag werden dann praktische Hinweise zur Arbeit mit DFS und dem LoadLeveler gegeben.
Datum: 5.10. und 6.10.95
Kursinhalt:
Über Jahre hinweg war auf Großrechnern des Rechenzentrums das Netzwerkanalyseprogramm SCEPTRE im Einsatz gewesen, mit dem eine Reihe von Schaltungen simuliert und über Ersatzschaltbilder auch neuartige Bauelemente (z.B. Josephson-Kontakte) auf dem Rechner getestet worden sind.
Eine Stärke von SCEPTRE besteht in der besonderen Berücksichtigung nichtlinearer Effekte, die mittels arithmetischer Anweisungen, Tabellen, mathematischer Funktionen, gesteuerter Spannungs- und Stromquellen sowie anderer Netzwerkgrößen beschrieben werden können. Ein weiteres Merkmal ist die Möglichkeit zur Verwendung eigener Parameter und ihrer zeitlichen Ableitungen. Damit lassen sich Differentialgleichungssysteme, die mit elektrischen Netzwerken gekoppelt sein können, gleichzeitig lösen. Auch nichtelektrische (z.B. mechanische) und sogar interdisziplinäre (z.B. mechanisch-elektronische- "Mechatronik") Problemstellungen, die sich durch Differentialgleichungen darstellen lassen, können auf diese Weise simuliert werden. Die Eingabe erfolgt in diesen Fällen entweder direkt in mathematischer Form oder über ein elektrisches Analogon.
Obwohl es sich bei SCEPTRE um ein Batchprogramm handelt, läßt es sich auf dem PC (unter LINUX) gut handhaben. Die Rechenergebnisse werden in Tabellenform fortlaufend ausgegeben und können mit gnuplot und anderen Graphikpaketen dargestellt werden; eine Schnittstelle für Online-Graphiken ist ebenfalls vorhanden.
Für eine Vorführung von SCEPTRE 90 konnte das RZ den Fachmann (und Portierer nach LINUX) für dieses Programm, Herrn Dr.-Ing. Wolf-Rainer Novender von der FH Friedberg, gewinnen:
Datum: Donnerstag, 19.10.95
Bei elektrotechnischen Aufgabenstellungen ist die Effizienzsteigerung durch Einsatz geeigneter Softwarepakete erheblich. Die Schaltungen werden komplexer, die Leiterplatten dichter belegt, die Bauteile stärker integriert - und manchmal steigen sogar die verwendeten Frequenzen. Mancher Schaltungsentwurf ist ohne Rechnerhilfe überhaupt nicht mehr zu realisieren.
Aus diesem Grund sind innerhalb unseres Campus mehrere Dutzend Programme insbesondere für Platinen-Layout und Schaltungssimulation im Einsatz, vor allem die Programme top-CAD und PSPICE. Künftig sind auch Programme zur Beurteilung der elektromagnetischen Verträglichkeit (EMV) von Geräten zu erwarten.
Erfreulicherweise sind bei PSPICE in den zurückliegenden Wochen erhebliche Preissenkungen eingetreten, so daß zusätzliche Lizenzen jetzt schon für weniger als DM 3000,- erhältlich sind. Dies hängt offensichtlich auch mit der Marktlage im Softwarebereich zusammen, denn die einfacheren Programme wie TopSPICE und SCEPTRE 90 (siehe auch Bericht auf Seite 16) können bereits für einen Bruchteil dieses Betrages erworben werden.
Zum Austausch von Erfahrungen mit den vorhandenen Paketen und zur eventuellen gemeinsamen Bestellung von Softwarepaketen lade ich auch in diesem Jahr ein zum
Themen (voraussichtlich):
Probleme mit PC oder Workstation? Rent-a-HiWi!
Neuer Vor-Ort-Service des RZ für PC- und Workstation-Nutzer
Dieter Oberle
Umrüstung des Vektorrechners SNI S600/20
N. Geers
an Herrn N. Geers (Tel. 608-3755, e-mail: geers@rz.uni-karlsruhe.de) oder
an Herrn P. Schroth (Tel. 608-3752, e-mail: schroth@rz.uni-karlsruhe.de).
Glasfaserverbindung zur Westhochschule und zur Fachhochschule in Betrieb
Reinhard Strebler
WWW-Zwischenspeicher: Der Proxy/Cache
Andreas Ley![]()
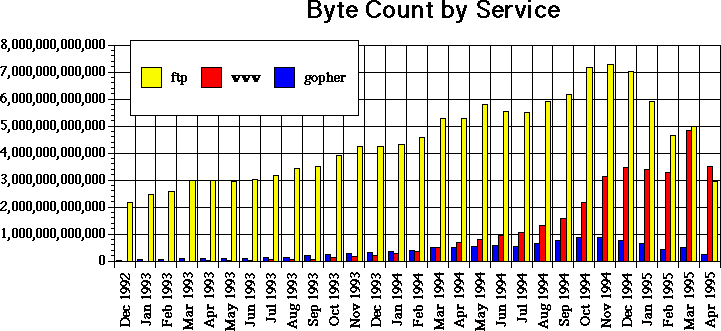
Die Zahlen sind relativ zu sehen: seit Ende 1994 hat die NSF begonnen, den
Backbone durch ein Netz von NAPs zu ersetzen, so daß die Meßwerte auf dem
Backbone sinken; seit Mai 1995 ist der Backbone außer Betrieb.)Das Dilemma der begrenzten Kapazitäten
Die Außenleitungen der Universität sind in ihrer Kapazität beschränkt,
ein noch entscheidenderer Flaschenhals ist die USA-Anbindung des DFN,
die auch bei einigen "innerdeutschen" Verbindungen in Anspruch genommen
werden muß.
Da dies dazu führt, daß man tagsüber manchmal überhaupt nicht mehr
"in die weite Welt" hinauskommt, gilt es, den Verkehr über diese Leitungen
auf das Notwendigste zu beschränken.
Eine Möglichkeit der Beschränkung (und sicher die am wenigsten restriktive)
ist die Vermeidung der Übertragung redundanter Information, wie dies
im World Wide Web oft gegeben ist, wenn viele Leute sich die
gleichen Seiten anschauen.
Ziel ist es also, jede Seite nur einmal über die Außenleitungen
zu übertragen und danach lokal zu halten und geeignet im Campus zu verteilen.
Der WWW-Proxy als Stellvertreter
Um die Anfragen nach WWW-Seiten entsprechend zu koordinieren, ist es notwendig, diese
über einen zentralen Rechner der Universität laufen zu lassen.
Im World Wide Web ist ein solcher Mechanismus bereits vorgesehen:
Ein
Proxy kann HTTP-Anfragen (also das "eigentliche" WWW-Protokoll)
an andere WWW-Server weiterleiten, er kann aber auch andere Protokolle
wie FTP, Gopher oder WAIS umsetzen und damit den Zugriff auf diese
Protokollwelten auch für Browser ermöglichen, die diese Protokolle
selber nicht unterstützen.
Der WWW-Proxy als Cache
Die Funktionalität des WWW-Proxys läßt sich nun, dem Ziel der Lastvermeidung
entsprechend, dahingehend erweitern, daß alle Dokumente, die den Proxy
passieren, auf einer lokalen Platte
(Cache) zwischengespeichert werden.
Kommt nun eine zweite (dritte, etc.) Anfrage für dasselbe Dokument, kann der Proxy
dieses sofort aus dem Cache liefern, ohne den entfernten Rechner erneut kontaktieren
zu müssen.
Auf dem zentralen WWW-Server der Universität
www.uni-karlsruhe.de
ist ein solcher als
Cache
konfigurierter Proxy installiert; zum Zwischenspeichern von Dokumenten verfügt er über 2 GByte Plattenplatz.
Cache-Mechanismen
Natürlich verbleiben die Dokumente nicht für immer im Cache; zum
einen würde ihn dies zum Überlaufen bringen, zum anderen wären die
Dokumente irgendwann nicht mehr aktuell.
Deshalb wird jede Nacht ein Expire durchgeführt, das veraltete Dokumente
aus dem Cache löscht.
Die Zeit, in der ein Dokument veraltet, wird dabei dynamisch festgelegt.
Bei Dokumenten, die über HTTP verteilt werden, kann explizit vom Autor
des Dokumentes angegeben werden, wie lange es im Cache verbleiben soll;
ist eine solche Verweildauer nicht angegeben, wird vom Proxy 10% der
Zeit seit der letzten Änderung als Verweilzeit angenommen.
So verbleiben Dokumente, die sich selten ändern, lange im Cache und
helfen effektiv, die Netzlast zu verringern, während sich oft ändernde
Dokumente häufig auf ihre Aktualität hin überprüft werden.
FTP- und Gopher-Dokumente, die weder explizite noch implizite
Verweildauerangaben ermöglichen, werden z.Zt. für eine Woche gehalten,
FTP-Verzeichnisinhalte für einen Tag.
Suchanfragen, also dynamisch erzeugte Dokumente, werden gar nicht gecacht.
Benutzung des Proxy/Caches
Der vom RZ installierte Proxy kann HTTP-, FTP-, Gopher- und WAIS-Anfragen
weiterleiten; dies ist aber nur für Anfragen außerhalb der Universität sinnvoll.
Um den
Proxy zu benutzen und damit in den Genuß der schnelleren Antwortzeiten
dank Cache zu kommen, muß der Browser so eingestellt werden, daß er den
Proxy zum gegebenen Zeitpunkt richtig anspricht.
Die Einstellungen unterscheiden sich je nach Betriebssystem und Browser.
http_proxy,
ftp_proxy,
gopher_proxy und
wais_proxy auf
http://www.uni-karlsruhe.de/
(der / am Ende ist wichtig!).
Zusätzlich ist die Variable no_proxy auf
uni-karlsruhe.de,uka.de einzustellen; hiermit wird die
Liste der Domains spezifiziert, für die der Proxy nicht
konsultiert werden soll..profile eintragen:
Wer die C- oder TC-Shell benutzt, trägt folgendes in sein
http_proxy=http://www.uni-karlsruhe.de/
ftp_proxy=http://www.uni-karlsruhe.de/
gopher_proxy=http://www.uni-karlsruhe.de/
wais_proxy=http://www.uni-karlsruhe.de/
export http_proxy ftp_proxy gopher_proxy wais_proxy
.login ein:
Auf den vom RZ installierten Workstations sind diese Einstellungen
bereits im System eingetragen und müssen nicht vom einzelnen
Benutzer vorgenommen werden.
Wenn man überprüfen will, ob der Proxy verwendet wird, kann man
setenv http_proxy http://www.uni-karlsruhe.de/
setenv ftp_proxy http://www.uni-karlsruhe.de/
setenv gopher_proxy http://www.uni-karlsruhe.de/
setenv wais_proxy http://www.uni-karlsruhe.de/
echo $http_proxy eingeben; wenn diese Variable gesetzt
ist, wird der Proxy angesprochen.www.uni-karlsruhe.de
bzw. 80 eingesetzt werden.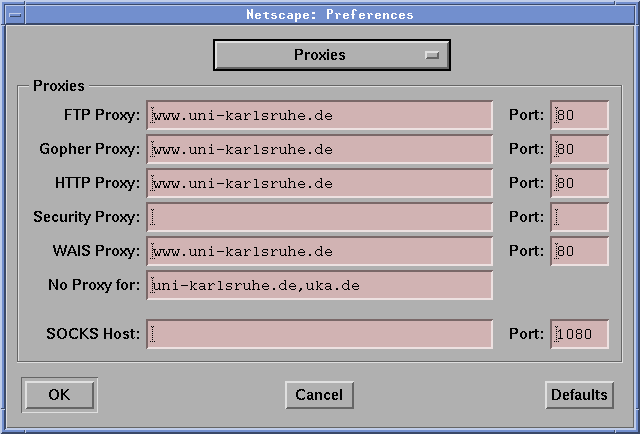
www.uni-karlsruhe.de:80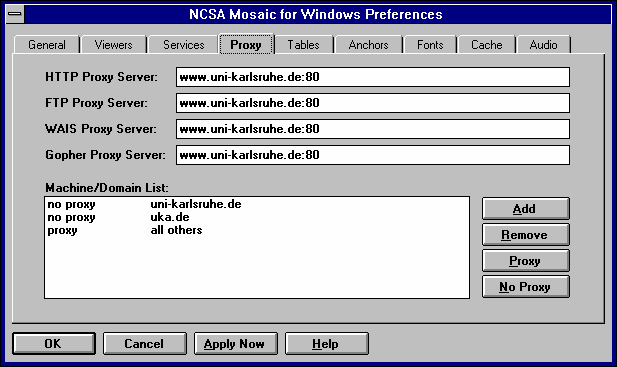
www.uni-karlsruhe.de
bzw. 80 eingesetzt werden.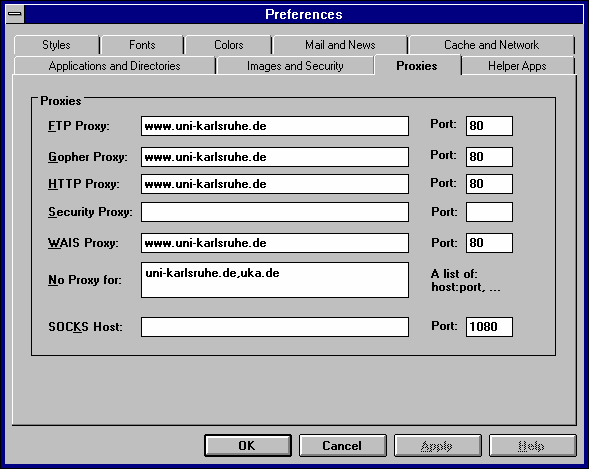
www.uni-karlsruhe.de bzw. 80
eingetragen werden.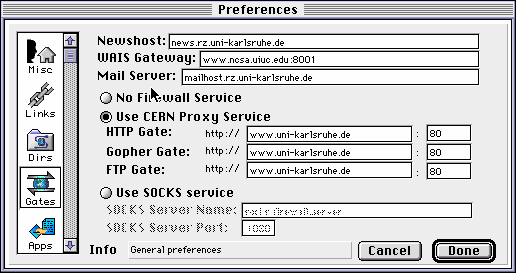
www.uni-karlsruhe.de
und 80 eingetragen werden.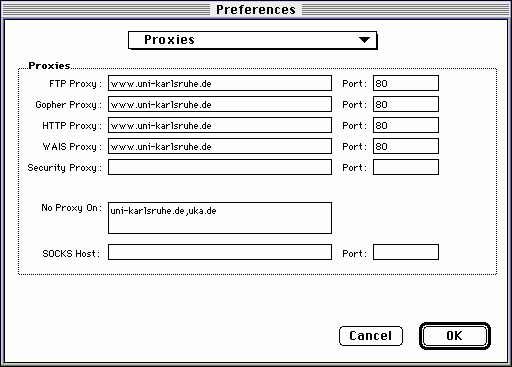
Für WWW-Einsteiger: HTML-Kurzanleitung
Andreas LeyÜbersicht
Was ist eigentlich HTML?
HTML heißt HyperText Markup Language, ist also eine Sprache, um Hypertexte
mit Markierungen zu versehen.
(Genaugenommen ist HTML ein SGML-DocumentType.)
HyperText ist einfach normaler Text (für Informatiker: Knoten),
der Verbindungen (für Informatiker: Kanten) zu anderen
Dokumenten hat.
So entsteht ein richtiges Netz (für Informatiker: Graph) von
Dokumenten, das sich
World Wide Web nennt.
Diesen Verbindungen kann man durch einfaches Auswählen nachgehen.
Wie sieht HTML aus?
HTML sieht zuerst einmal wie ganz normaler Text aus.
Und das ist es eigentlich auch.
Nur daß dazwischen spezielle Zeichenketten auftauchen, die die HTML-Befehle
darstellen.<) an, dann
kommt der Name des Tags und zum Abschluß ein Größerzeichen
(>), also etwa so: <NAME>.
Es gibt Tags, die mitten im Text auftauchen (sie werden als
leere Tags bezeichnet) und andere, die einen Teil des
Textes umschließen. Dazu gibt es neben dem schon beschriebenen
Opening Tag noch einen Closing Tag, der sich von
ersterem nur durch einen Slash ( /) vor dem Namen
unterscheidet: </NAME>.
Außerdem gibt es noch Tags, die Attribute haben, mit denen man das Verhalten
der Tags beeinflußen kann.
Solche Attribute stehen zwischen dem Namen und dem Größerzeichen und
werden durch Leerzeichen voneinander getrennt.
Manche Attribute haben zusätzlich noch einen Wert, dieser wird dann mit einem
Gleichheitszeichen an das Attribut angehängt.
Enthält der Wert selbst Leerzeichen, sollte man ihn in Anführungszeichen
einschließen:
<NAME ATTR="Wert">.
Ein ganz komplizierter Tag würde also so aussehen:
Da HTML als ASCII-Text definiert ist, dürfen auch keine Zeichen über 127
verwendet werden.
Das heißt zunächst auch erst einmal, daß keine Umlaute direkt in den Text
geschrieben werden dürfen.
Um dennoch Umlaute und Sonderzeichen im Text unterzubringen, dienen die
sogenannten Entities, die eine Umschreibung für Umlaute sind.
<NAME ATTR1 ATTR2="Wert">
Irgendwelcher Text
</NAME>
Achtung SGML-Freaks: Entities sind eigentlich SGML-Makros, können
aber nicht als solche verwendet werden, da die Browser keinen
SGML-Parser haben, sondern nur bestimmte vordefinierte Entities.&) an, dann folgt
der Name des Entitys, abgeschlossen mit einem Semikolon (;).
Der Ampersand selber hat dann natürlich auch ein eigenes Entity;
ebenso braucht man für das Größer- und das Kleinerzeichen auch eigene Entities.
ä:
Auf den RZ-Workstations steht das Kommando htmlconv zur
Verfügung, mit dem man in einem Dokument die ISO-Umlaute in
HTML umwandeln kann.
ä
ö: ö
ü: ü
ß: ß
Ä: Ä
Ö: Ö
Ü: Ü
&: &
<: <
>: >
Der prinzipielle Aufbau eines Dokuments
Bei HTML geht alles ganz hierarchisch zu.
Das fängt damit an, daß man sich auf die entsprechende Document Type
Definition bezieht (HTML ist ja ein SGML-Typ), indem die erste Zeile
eines Dokuments lautet:
Um ein HTML-Dokument jetzt als solches zu kennzeichnen, wird es zuallererst in einen
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN">
<HTML>-Tag eingeschlossen.
Das eigentliche Dokument gliedert sich dann in einen
Header und einen
Body.
Der Header wird durch
<HEAD>-Tags umschlossen; hier stehen allgemeine
Informationen über das Dokument, aber nichts, was zu irgendeiner Ausgabe führt.
Der Body ist der eigentliche Informationsträger,
er wird durch <BODY>-Tags begrenzt und enthält all das, was
später zur Anzeige kommen soll.
Auf den RZ-Workstations steht das Kommando newhtml zur
Verfügung, mit dem ein leeres Dokument anlegen werden kann, das diesen
Konventionen entspricht.
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN">
<HTML>
<HEAD>
Header-Elemente
</HEAD>
<BODY>
Body-Elemente
</BODY>
</HTML>
Was im Header steht
Im Header stehen Informationen über das Dokument, aber noch kein Inhalt,
also nichts, was zu irgendeiner Ausgabe führt.
Es handelt sich vielmehr um Meta-Informationen, die dem Browser etwas
über das Dokument erzählen; wie es heißt, wer es gemacht hat und vieles mehr.<TITLE> gekennzeichnet.
Der Titel sollte ein Dokument auch außerhalb seines Kontextes kennzeichnen,
er wird z. B. für die Anzeige in der History, der Hotlist
oder als Ausgabe automatischer Suchen auf dem Netz benutzt.
Er sollte, alleinstehend, eine Aussage über das Dokument geben, anhand der
man das Dokument identifizieren.
Insbesondere sollte man Titel wie "Einführung" oder "Überblick" oder
"Meine Homepage" vermeiden - das sind Überschriften!<LINK>-Element,
das für Verbindungen zwischen Dokumenten genutzt werden kann; Hauptaufgabe
ist gegenwärtig die Kennzeichnung des Urhebers eines Dokuments.
Dazu erhält der <LINK>-Tag ein Reverse-Relationship-Attribut
(REV) mit dem Wert "made", es kennzeichnet also,
wer das Dokument "gemacht" hat.
Der Autor wird dann im HREF-Attribut aufgeführt, er wird durch
eine mailto:-URL gekennzeichnet, die eine E-mail-Adresse
enthält.
Einige Browser sind aufgrund dieser Kennzeichnung bereits in der Lage,
Kommentare direkt an den Autor zu schicken.<HEAD>-Tags geklammert.
Ein typischer Header könnte also so aussehen:
<HEAD>
<TITLE>Dokument-Titel</TITLE>
<LINK REV="made" HREF="mailto:user@rz.uni-karlsruhe.de">
</HEAD>
Was im Body steht
Im Body steht der Inhalt des Dokuments, also all das, was angezeigt werden
soll.
Dies kann zunächst einmal ganz normaler ASCII-Text sein.
Dabei muß auf Zeilenumbrüche und ähnliches nicht geachtet werden, dafür
sorgt nämlich der Browser oder WWW-Client.
Und da jeder Browser anders funktioniert, andere Zeichensätze oder
Fenstergrößen hat, sollte man auch tunlichst vermeiden, irgendwelche Annahmen
darüber zu treffen.Überschriften
HTML stellt sechs verschiedene Level von Überschriften zur Verfügung,
die mit den Tags <H1> bis <H6>
markiert werden.
Ein mit einer Überschrift versehener Text sähe also so aus:
<H1>Überschrift</H1>
Ganz ganz viel Text.
Abschnitte und Umbrüche
Ein einziger riesiger Text ist auch nicht sehr lesbar, deswegen läßt er sich
in einzelne Abschnitte unterteilen.
Dazu dient der <P>-Tag, der zwischen zwei Abschnitte
gestellt wird und zwei Abschnitte voneinander trennt.
Anmerkung: Mit den neuen Versionen von HTML ändert sich die Benutzung
des Ganz viel Text.<P>
Noch mehr Text.
<P>-Tags dahingehend, daß er nun einen Abschnitt
umschließt, statt zwei Abschnitte zu trennen.
Leider beherrschen die gängigen Browser diese Verwendung noch nicht
korrekt, so daß man sich noch an die alte Definition halten sollte.<BR>-Tag.
Er wird genau wie <P> verwendet.<HR>-Tag erzeugt und genau wie
der <P>-Tag zwischen die zu trennenden Abschnitte
gesetzt.<BLOCKQUOTE>-Tags, die im Gegensatz
zu den anderen nicht leer sind.
Zitate und Beispiele werden oft eingerückt dargestellt.
Ein Beispiel für ein Zitat:
Die Tags Einfacher Text
<BLOCKQUOTE>
Zitierter Text
</BLOCKQUOTE>
Weiterer Text
<P>, <BR> und
<HR> sollten nur dann verwendet werden,
wenn ansonsten der Text zu einem Abschnitt zusammenfließen würde.
Insbesondere sollten nicht mehrere aufeinander folgen, auch wenn
manche Browser dies tolerieren; andere erzeugen damit fast leere
Seiten.
Ebenso brauchen vor oder nach anderen Tags, die ebenfalls eine
Trennung des Textes bewirken (z. B. Überschriften), keine
Abschnittstrenner zu stehen.
Listen
Manche Informationen lassen sich besser als eine Auflistung denn als
fließender Text präsentieren.
HTML bietet hierzu drei grundlegende Listentypen an.
Der einfachste Typ ist die ungeordnete Liste, was jetzt aber nicht heißt,
daß die Listenelemente wild durcheinander angezeigt werden; dies soll
lediglich ausdrücken, daß die Liste keine definierte Abfolge darstellt.
Eine solche Liste wird durch <UL>-Tags begrenzt,
die einzelnen Listenelemente werden durch <LI>
eingeleitet:
Für eine definierte Abfolge, wie sie z. B. in einer Gebrauchsanweisung
auftaucht, steht die geordnete Liste zu Verfügung, wobei
der Browser dafür sorgt, daß dies auch zum Ausdruck kommt (z. B.
durch fortlaufende Nummern vor den Einträgen).
Eine geordnete Liste funktioniert genau wie eine ungeordnete, nur ist
jetzt <UL>
<LI>Ein Eintrag
<LI>Noch ein Eintrag
</UL>
<OL> statt <UL> zu
verwenden.<DT> eingeleitet,
die zugehörige Erklärung durch <DD>:
<DL>
<DT>Ein Eintrag
<DD>und der zugehörige Text
<DT>Ein anderer Eintrag
<DD>und der dazugehörige Text
</DL>
Hervorhebungen und Stile
Natürlich sind in HTML Texthervorhebungen möglich, sie sollten sich aber
möglichst nur auf die Struktur beziehen.
Dazu dienen die strukturellen Markierungen <EM>
(Hervorhebung) und <STRONG> (Betonung).
Zur Darstellung computerbezogener Daten eignet sich <CODE>.
Der Browser entscheidet selber, wie er welche Markierung anzeigt,
üblich ist aber kursiv zur Hervorhebung und fett zur Betonung, so verfügbar.
<CODE>-Tags werden oft als nichtproportionaler Zeichensatz
dargestellt.
Neben den strukturellen Markierungen gibt es auch noch explizite Anweisungen
für kursiven Text (<EM>Hervorgehobener</EM> und <STRONG>betonter</STRONG> Text
<I>),
fetten Text (<B>),
unterstrichenen Text (<U>)
oder Schreibmaschinentext (<TT>).
Dies ist aber keine Garantie dafür, daß der Text dann auch wirklich so
erscheint, da manche Browser ihn nicht wie gewünscht darstellen können!
Man sollte daher nach Möglichkeit auf diese Markierungen verzichten und
auf die strukturellen zurückgreifen.
Vorformatierter Text
Beim Übertragen fertiger ASCII-Dokumente nach HTML kommt es oft vor, daß
man einen schön gesetzten Text wie z. B. eine Tabelle hat, die durch den
automatischen Umbruch oder durch die proportionalen Zeichensätze zerstört
werden würde.
Für solche Fälle stehen die <PRE>-Tags zur Verfügung,
die einen Text in einem nichtproportionalen Zeichensatz darstellen
und vorgegebene Zeilenumbrüche beachten:
<PRE>Die erste Zeile
Die letzte Zeile</PRE>
Adressen
Für die Angabe von Adressen gibt es die <ADDRESS>-Tags:
<ADDRESS>
Rechenzentrum der Universität Karlsruhe
Zirkel 2
Postfach 6980
D-76128 Karlsruhe
</ADDRESS>
Hyperlinks
Das interessanteste an Hypertext sind die Hyperlinks, also die Verbindungen
zu anderen Dokumenten. Dazu muß man aber erst einmal eine Möglichkeit haben,
andere Dokumente zu spezifizieren; dies tun die URLs (Uniform Resource Locator).
Viele Browser zeigen die URL des aktuellen Dokuments an; sie setzt sich
zusammen aus dem Protokoll, gefolgt von einem Doppelpunkt, zwei
Slashs //, die den Host einleiten, und dem Pfad
zu dem Dokument auf dem Host.
Der Pfad hat dabei nur bedingt mit den UNIX-Dateipfaden zu tun,
die Interpretation ist dem durch Protokoll und Host
spezifizierten Server überlassen.
HTTP-Server übertragen aber im allgemeinen die UNIX-Dateipfade auf die URLs,
allerdings ist der Startpunkt nicht das Root-Verzeichnis, sondern
(aus Sicherheitsgründen) ein spezifisches Dokumentenverzeichnis.
So wird aus der URL
der Dateipfad
http://www.uni-karlsruhe.de/Betrieb/HTML/Kurzanleitung.html
URLs, die mit einer Tilde (/usr/local/etc/httpd/htdocs/Betrieb/HTML/Kurzanleitung.html
~) anfangen, spezifizieren
Benutzerverzeichnisse; für RZ-Benutzer liegt der Startpunkt dann in
$HOME/.public_html.
Jetzt wird die URL
abgebildet auf den Dateipfad
http://www.uni-karlsruhe.de/~user/Homepage.html
Trotzdem kann man mit URLs ähnlich umgehen wie mit Dateipfaden: Man muß
beispielsweise
in einem Verweis eines Dokument nicht immer die ganze URL angeben, wenn sich das andere Dokument
auf demselben Server befindet, sondern kann lediglich den Pfad
angeben; der Browser setzt dann selbständig Protokoll und Host des aktuellen Dokuments ein.
Man sollte von dieser Möglichkeit Gebrauch machen, um so große Schwierigkeiten zu vermeiden, wenn sich einmal der Name des Rechners ändert, auf dem sich die
Dokumente befinden.
Gehören zwei Dokumente zu einer Hierarchie von Dokumenten, sollte man sogar eine
noch lokalere Art von URLs anwenden, indem man den relativen Pfad
angibt, genau wie bei Dateipfaden.
So würde die URL
/home/ws/user/.public_html/Homepage.html
abgebildet auf den Dateipfad
../Proxy/
wobei noch hinzukommt, daß der Server, wenn nur ein Verzeichnis in der
URL angegeben ist, automatisch nach einer Datei /usr/local/etc/httpd/htdocs/Betrieb/Proxy/index.html
index.html
sucht.
Mit diesen relativen URLs vermeidet man Probleme, wenn die
Dokumenthierarchie einmal an eine andere Stelle im Dokumentenbaum verschoben
werden soll.<A>-Tags (A steht für Anchor, zu deutsch Anker),
dem öffnenden Tag wird dabei die URL im HREF-Attribut
übergeben. Der Textabschnitt, der als Anker dienen soll, wird von den
<A>-Tags eingeschlossen.
Den <A HREF="../Proxy/">Proxy</A> sollte jeder verwenden.
Bilder
Bilder sind externe Bestandteile und werden deshalb, ähnlich wie Hyperlinks,
unter Angabe ihrer URL eingebunden.
Über die URLs gilt dabei das oben gesagte, insbesondere genügt es, bei
Bildern, die sich im gleichen Verzeichnis wie das Dokument befinden,
den Dateinamen des Bildes ohne weitere Pfadangaben zu spezifizieren.<IMG>-Tag,
die URL des Bildes wird im im SRC-Attribut übergeben.
Zusätzlich kann mit dem Attribut ALIGN, das die Werte
BOTTOM, MIDDLE und TOP annehmen darf,
die Plazierung des Bildes im laufenden Text angegeben werden.ALT-Attribut
angibt, oder (in begründeten Dekorationsfällen) auch einen leeren Text,
der so zumindest vermeidet, daß ein Textbrowser nur [IMAGE]
anzeigt.
<IMG SRC="/Icons/Logos/Unilogo.gif" ALT="">
Kommentare
Kommentare in HTML werden zwischen <!-- und -->
eingeschlossen:
Achtung: Marken lassen sich nicht durch Kommentare ausblenden!
Zumindest die gängigen Browser lassen nach dem ersten <!-- Dieser Abschnitt muss nochmal ueberarbeitet werden -->
>
alle Kommentare Kommentare gewesen sein.
Wem das noch nicht genug ist, der kann sich
alles über HTML
vom WWW Konsortium ansehen.
Dort gibt es u.a. einen Abschnitt darüber, welche Tags nun wie geschachtelt
werden dürfen.
Englischkurse für das Operating im Rechenzentrum
Dr. Rüdiger Weiß
Wissenschaftler aus Tschechien Gast am Rechenzentrum
Dr. Rüdiger Weiß
bezogen werden. Eine Veröffentlichung in der Zeitschrift Applications of Mathematics wird angestrebt.
Anwendungssoftware
Floating License für PATRAN 3 Release 1.4-1
Dr. Paul Weberftnchek Project Files für numerische Unterprogrammbibliotheken

Veranstaltungen
Einführungskurs in ABAQUS 5.4
Dr. Paul Weber
Zeit: jeweils 9.00 - 13.00 Uhr,
ab 14.00 Uhr Übungen an den IBM RS6000 Workstations
Ort: RZ, Raum -101, UG
1. Tag:
3. Tag:
4. Tag:
Alle Teilnehmer bekommen die Kursunterlagen zur Verfügung gestellt. Interessenten melden sich bitte telefonisch (Tel. -4035) oder über e-mail (paul.weber@ rz.uni-karlsruhe.de) an.Einführung von DCE und LoadLeveler im AB-Pool
Zeit: jeweils 14.00 - 15.30 Uhr
Ort: RZ, Raum 217, 2. OG
DCE/DFS ist ein globales Filesystem und bietet gegenüber anderen verteilten Filesystemen Vorteile bei der Sicherheit, Verfügbarkeit und Performance. Der IBM LoadLeveler wurde vom RZ dahingehend angepaßt, daß im Batchbetrieb auf Daten im DFS zugegriffen werden kann. Mit dem LoadLeveler lassen sich Jobs auf einem Workstationcluster so verteilen, daß die Maschinen gleichmäßig genutzt werden.
Vorführung von SCEPTRE 90 unter LINUX
Dieter Kruk
Zeit: 16.45 bis 17.30 Uhr
Ort: RZ, Raum 217, 2 OG.
Herr Dr.-Ing. Novender wird schwerpunktmäßig die Handhabung des Programms, die Eingabedaten und den Simulationsablauf anhand von drei Beispielen vorstellen (Marx'scher Stoßgenerator, Gleichstromrelais, Magnetisierungsstrom mit Hystereseverlusten und Fourieranalyse). Alle Interessenten lade ich hierzu herzlich ein.Jahrestreffen der Anwender elektrotechnischer Software
Datum: Donnerstag, 19.10.95,
Zeit: 16.00 bis 16.45 Uhr
Ort: RZ, Raum 217, 2.OG
RZ-Webmaster / 13. September 1995
![]()
![]()